Веб-скрейпинг – это автоматизированный процесс извлечения данных с интересующих страниц сайта по определенным правилам.
Возможные сферы применения веб-скрейпинга:
- Отслеживание цен на товары в интернет-магазинах.
- Извлечение описаний товаров и услуг, получение числа товаров и картинок в листинге.
- Извлечение контактной информации (адреса электронной почты, телефоны и т.д.).
- Сбор данных для маркетинговых исследований (лайки, шеры, оценки в рейтингах).
- Извлечение специфичных данных из кода HTML-страниц (поиск систем аналитики, проверка наличия микроразметки).
- Мониторинг объявлений.
Основными способами веб-скрейпинга являются методы разбора данных используя XPath, CSS-селекторы, XQuery, RegExp и HTML templates.
- XPath представляет собой специальный язык запросов к элементам документа формата XML / XHTML. Для доступа к элементам XPath использует навигацию по DOM путем описания пути до нужного элемента на странице. С его помощью можно получить значение элемента по его порядковому номеру в документе, извлечь его текстовое содержимое или внутренний код, проверить наличие определенного элемента на странице. Описание XPath >>
- CSS-селекторы используются для поиска элемента его части (атрибут). CSS синтаксически похож на XPath, при этом в некоторых случаях CSS-локаторы работают быстрее и описываются более наглядно и кратко. Минусом CSS является то, что он работает лишь в одном направлении – вглубь документа. XPath же работает в обе стороны (например, можно искать родительский элемент по дочернему). Таблица сравнения CSS и XPath >>
- XQuery имеет в качестве основы язык XPath. XQuery имитирует XML, что позволяет создавать вложенные выражения в таким способом, который невозможен в XSLT. Описание XQuery >>
- RegExp – формальный язык поиска для извлечения значений из множества текстовых строк, соответствующих требуемым условиям (регулярному выражению). Описание RegExp >>
- HTML templates – язык извлечения данных из HTML документов, который представляет собой комбинацию HTML-разметки для описания шаблона поиска нужного фрагмента плюс функции и операции для извлечения и преобразования данных. Описание HTML templates >>
Обычно при помощи парсинга решаются задачи, с которыми сложно справиться вручную. Это может быть веб скрейпинг описаний товаров при создании нового интернет-магазина, скрейпинг в маркетинговых исследованиях для мониторинга цен, либо для мониторинга объявлений (например, по продаже квартир). Для задач SEO-оптимизации обычно используются узко специализированные инструменты, в которых уже встроены парсеры со всеми необходимыми настройками извлечения основных SEO параметров.
BatchURLScraper
Существует множество инструментов, позволяющих осуществлять скрейпинг (извлекать данные из веб-сайтов), однако большинство из них платные и громоздкие, что несколько ограничивает их доступность для массового использования.
Поэтому нами был создан простой и бесплатный инструмент – BatchURLScraper, предназначенный для сбора данных из списка URL с возможностью экспорта полученных результатов в Excel.
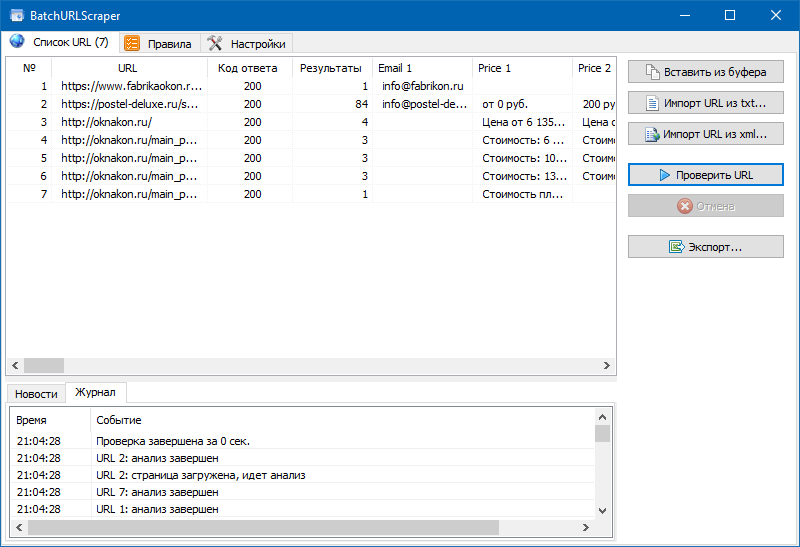
Интерфейс программы достаточно прост и состоит всего из 3-х вкладок:
- Вкладка «Список URL» предназначена для добавления страниц парсинга и отображения результатов извлечения данных с возможностью их последующего экспорта.
- На вкладке «Правила» производится настройка правил скрейпинга при помощи XPath, CSS-локаторов, XQuery, RegExp или HTML templates.
- Вкладка «Настройки» содержит общие настройки программы (число потоков, User-Agent и т.п.).
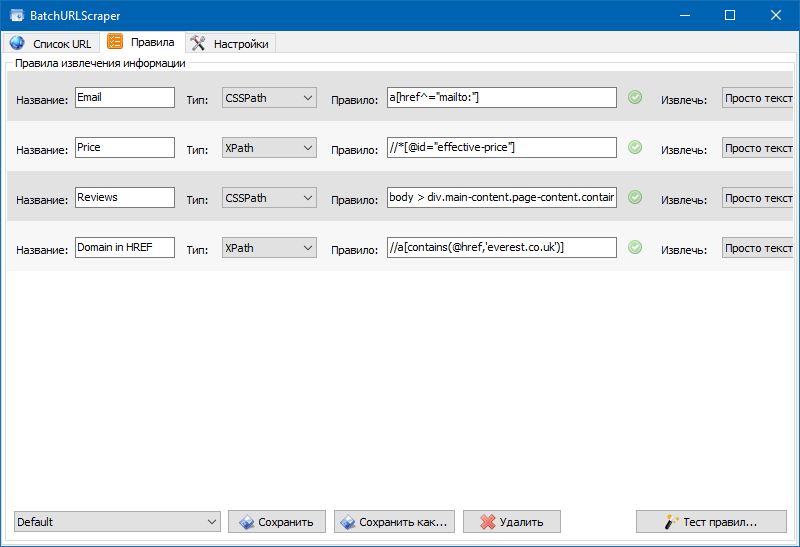
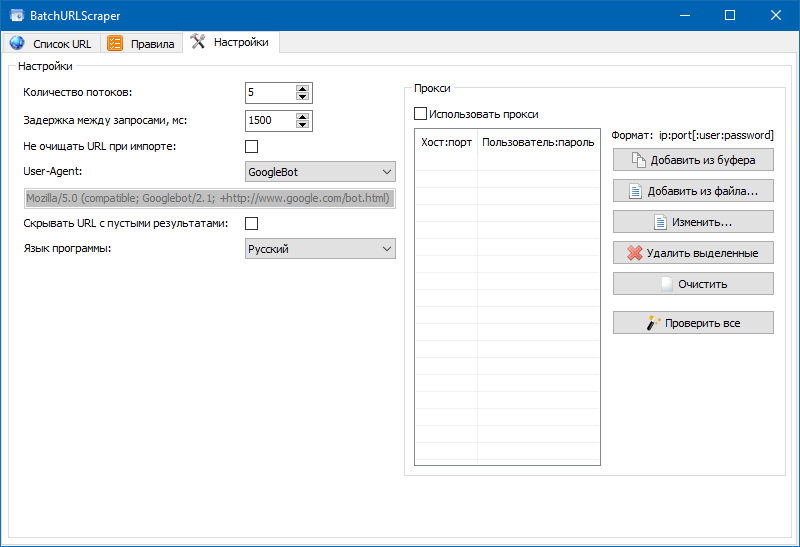
Также нами был добавлен модуль для отладки правил.
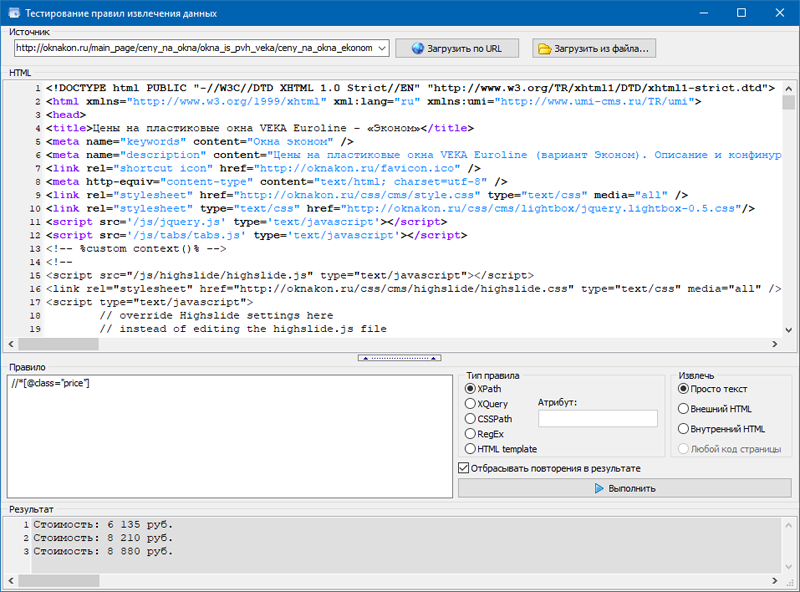
При помощи встроенного отладчика правил можно быстро и просто получить HTML-содержимое любой страницы сайта и тестировать работу запросов, после чего использовать отлаженные правила для парсинга данных в BatchURLScraper.
Разберем более подробно примеры настроек парсинга для различных вариантов извлечения данных.
Извлечение данных со страниц сайтов в примерах
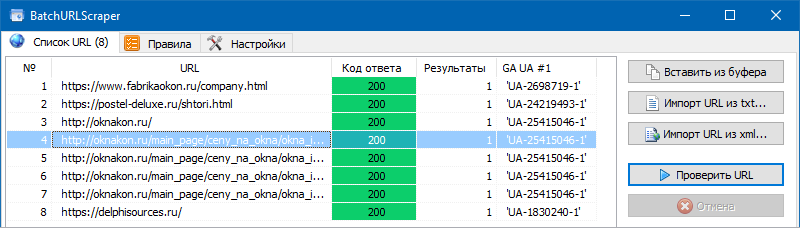
Так как BatchURLScraper позволяет извлекать данные из произвольного списка страниц, в котором могут встречаться URL от разных доменов и, соответственно, разных типов сайта, то для примеров тестирования извлечения данных мы будем использовать все пять вариантов скрейпинга: XPath, CSS, RegExp, XQuery и HTML templates. Список тестовых URL и настроек правил находятся в дистрибутиве программы, таким образом можно протестировать все это лично, используя пресеты (предустановленные настройки парсинга).
Механика извлечения данных
1. Пример скрейпинга через XPath.
Например, в интернет-магазине мобильных телефонов нам нужно извлечь цены со страниц карточек товаров, а также признак наличия товара на складе (есть в наличии или нет).
Для извлечения цен нам нужно:
- Перейти на карточку товара.
- Выделить цену.
- Кликнуть по ней правой кнопкой мыши и нажать «Показать код элемента» (или «Inspect», если вы используете англоязычный интерфейс).
- В открывшемся окне найти элемент, отвечающий за цену (он будет подсвечен).
- Кликнуть по нему правой кнопкой мыши и выбрать «Копировать» > «Копировать XPath».
Для извлечения признака наличия товара на сайте операция будет аналогичной.
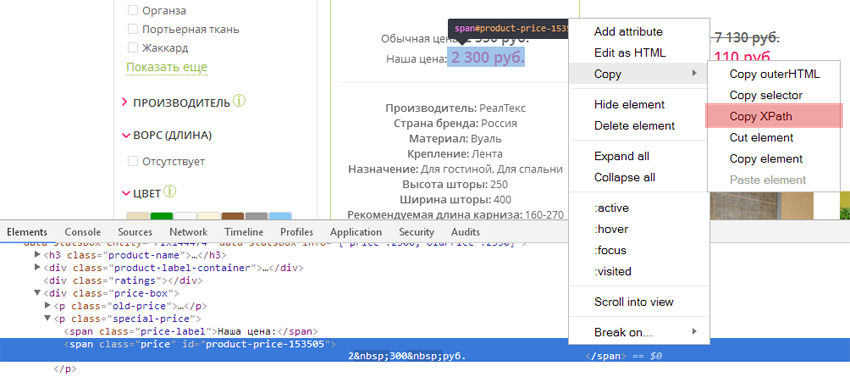
Так как типовые страницы обычно имеют одинаковый шаблон, достаточно проделать операцию по получению XPath для одной такой типовой страницы товара, чтобы спарсить цены всего магазина.
Далее, в списке правил программы мы добавляем поочередно правила и вставляем в них ранее скопированные коды элементов XPath из браузера.
2. Определяем присутствие счетчика Google Analytics при помощи RegExp или XPath.
- XPath:
- Открываем исходный код любой страницы по Ctrl-U, затем ищем в нем текст «gtm.start», ищем в коде идентификатор UA-…, и далее также используя отображение кода элемента копируем его XPath и вставляем в новое правило в BatchURLScraper.
- RegExp:
- Поиск счетчика через регулярные выражения еще проще: код правила извлечения данных вставляем [‘](UA-.*?)[‘].
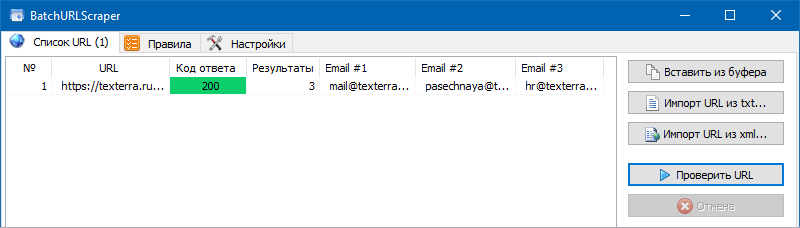
3. Извлечь контактный Email используя CSS.
Тут совсем все просто. Если на страницах сайта встречаются гиперссылки вида «mailto:», то из них можно извлечь все почтовые адреса.
Для этого мы добавляем новое правило, выбираем в нем CSSPath, и в код правила извлечения данных вставляем правило a[href^=»mailto:»].
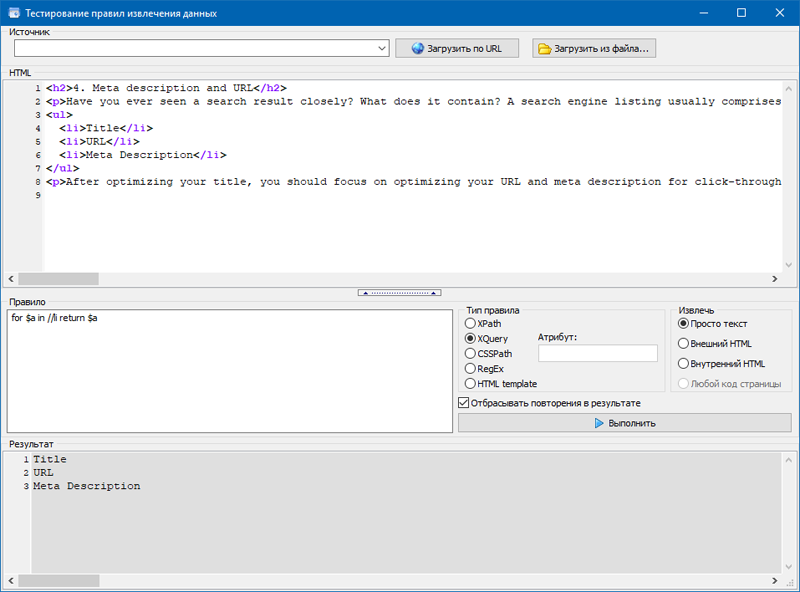
4. Извлечь значения в списках или в таблице при помощи XQuery.
В отличии от других селекторов, XQuery позволяет использовать циклы и прочие возможности языков программирования.
Например, при помощи оператора FOR можно получить значения всех списков LI. Пример:
Либо узнать, есть ли почта на страницах сайта:
- if (count(//a[starts-with(@href, ‘mailto:’)])) then «Есть почта» else «Нет почты»
5. Использование HTML templates.
В данном языке извлечения данных в качестве функций можно использовать XPath/XQuery, CSSpath, JSONiq и обычные выражения.
Тестовая таблица:
| 1 | aaa | other |
| 2 | foo | columns |
| 3 | bar | are |
| 4 | xyz | here |
Например, данный шаблон ищет таблицу с атрибутом id=»t2″ и извлекает текст из второго столбца таблицы:
- <table id=»t2″><template:loop><tr><td></td><td>{text()}</td></tr></template:loop></table>
Извлечение данных из второй строки:
- <table id=»t2″><tr></tr><tr><template:loop><td>{text()}</td></template:loop></tr></table>
А этот темплейт вычисляет сумму чисел в колонке таблицы:
- <table id=»t2″>{_tmp := 0}<template:loop><tr><td>{_tmp := $_tmp + .}</td></tr></template:loop>{result := $_tmp}</table>
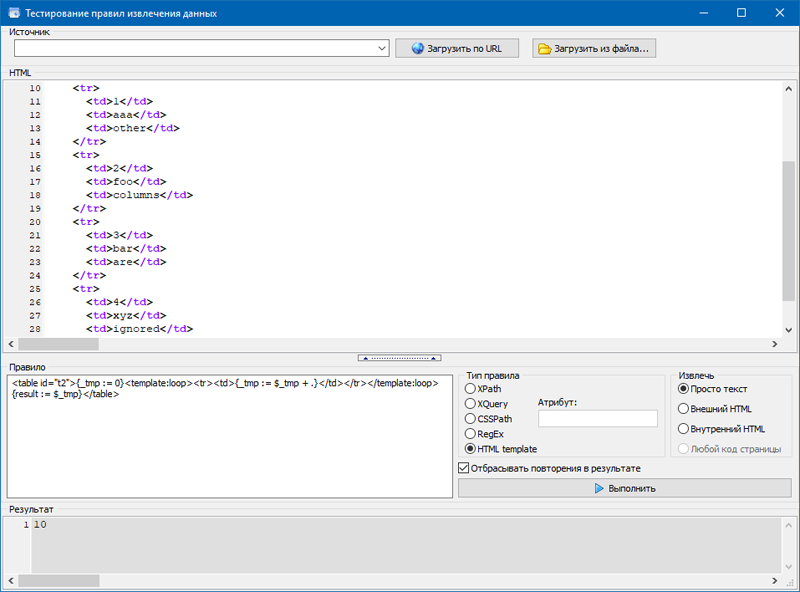
Таким образом, мы получили возможность извлекать практически любые данные с интересующих страниц сайтов, используя произвольный список URL, включающий страницы с разных доменов.
Ниже представлена таблица, с наиболее часто встречающимися правилами для извлечения данных.
Примеры кода для извлечения данных
В данной таблице мы собрали список наиболее часто встречающихся вариантов получения данных, которые можно извлечь используя различные типы экстракторов.
| Экстрактор | Выражение | Описание |
|
1. CSSPath
|
#comments>h4
|
Содержимое ID «comments» и в нем подзаголовка H4
|
|
2. CSSPath
|
*[src^=http://]
|
Поиск небезопасных ссылок на HTTP протокол
|
|
3. CSSPath
|
a[href^=https://yourdomain.com]
|
Поиск страниц, содержащих в гиперссылках абсолютный URL на ваш домен
|
|
4. CSSPath
|
a[href^=mailto:]
|
Поиск ссылок, содержащих в URL mailto:
|
|
5. CSSPath
|
a[itemprop=maps]:not([href=your_google_maps_url])
|
Поиск страниц, не содержащих определенный URL на карты Google
|
|
6. CSSPath
|
a[itemprop=maps][href=your_google_maps_url]
|
Поиск страниц, содержащих определенный URL на карты Google
|
|
7. CSSPath
|
body>noscript:has(iframe[src$=GTM-your_tracking_id]):first-child
|
Извлечение Google Tag Manager ID
|
|
8. CSSPath
|
head:has(link[rel=alternate][hreflang=es-es][href*=/es/])
|
Поиск страниц, содержащих href или hreflang =/es/
|
|
9. CSSPath
|
img[alt*=SiteAnalyzer]
|
Содержимое тега alt, если он содержит текст SiteAnalyzer
|
|
10. CSSPath
|
link[rel=canonical][href^=http://]
|
Поиск страниц, содержащих в канонических URL страницы с протоколом HTTP
|
|
11. CSSPath
|
link[rel=stylesheet][href^=http://]
|
Поиск не безопасных ссылок на HTTP протокол в ссылках на CSS файлы стилей
|
|
12. CSSPath
|
meta[name=description][content*=siteanalyzer]
|
Содержимое мета-тега description, если он содержит текст SiteAnalyzer
|
|
13. Regex
|
[‘](GTM-.*?)[‘]
|
Извлечение Google Tag Manager ID 1
|
|
14. Regex
|
[‘](GTM-\w+)[‘]
|
Извлечение Google Tag Manager ID 2
|
|
15. Regex
|
[‘](UA-.*?)[‘]
|
Извлечение Google Analytics ID
|
|
16. Regex
|
[a-zA-Z0-9][a-zA-Z0-9\.+-]+\@[\w-\.]+\.\w+
|
Ищем Email 1
|
|
17. Regex
|
[a-zA-Z0-9-_.]+@[a-zA-Z0-9-]+.[a-zA-Z0-9-.]+
|
Ищем Email 2
|
|
18. Regex
|
\w+
|
Ищем одиночные слова
|
|
19. XPath
|
//*[@hreflang]
|
Содержимое всех элементов hreflang
|
|
20. XPath
|
//*[@hreflang]/@hreflang
|
Конкретные значения элементов hreflang
|
|
21. XPath
|
//*[@id=»our_price»]
|
Парсинг цен 1
|
|
22. XPath
|
//*[@class=»price»]
|
Парсинг цен 2
|
|
23. XPath
|
//*[@itemprop]/@itemprop
|
Правила Itemprop
|
|
24. XPath
|
//*[@itemtype]/@itemtype
|
Типы схем структрурированных данных
|
|
25. XPath
|
//*[contains(@class, ‘watch-view-count’)]»
|
Число просмотров на Youtube
|
|
26. XPath
|
//*[contains(@class,’like-button-renderer-dislike-button’)])[1]
|
Число дизлайков ролика на Youtube
|
|
27. XPath
|
//*[contains(@class,’like-button-renderer-like-button’)])[1]
|
Число лайков ролика на Youtube
|
|
28. XPath
|
//a[contains(.,’SEO Spider’)]/@href
|
Ссылки, включающие анкор SEO Spider
|
|
29. XPath
|
//a[contains(@class, ‘my_class’)]
|
Получение страниц, содержащих гиперссылку с определенным классом
|
|
30. XPath
|
//a[contains(@href, ‘linkedin.com/in’) or contains(@href, ‘twitter.com/’) or contains(@href, ‘facebook.com/’)]/@href;
|
Ссылки на соцсети
|
|
31. XPath
|
//a[contains(@href, ‘site-analyzer.pro’)]/@href
|
Ссылки на внутренние страницы
|
|
32. XPath
|
//a[contains(@href,’screamingfrog.co.uk’)]
|
Извлечение ссылок с вхождением (полный код либо текст анкора)
|
|
33. XPath
|
//a[contains(@href,’screamingfrog.co.uk’)]/@href
|
Извлечение именно URL со вхождением
|
|
34. XPath
|
//a[contains(translate(., ‘ABCDEFGHIJKLMNOPQRSTUVWXYZ’, ‘abcdefghijklmnopqrstuvwxyz’),’seo spider’)]/@href
|
Регистрозависимый поиск
|
|
35. XPath
|
//a[not(contains(@href, ‘site-analyzer.pro’))]/@href
|
Ссылки на внешние страницы
|
|
36. XPath
|
//a[starts-with(@href, ‘mailto’)]
|
Все email на странице
|
|
37. XPath
|
//a[starts-with(@href, ‘tel:’)]
|
Все телефоны на странице
|
|
38. XPath
|
//div[@class=»example»]
|
Содержимое по классу
|
|
39. XPath
|
//div[@class=»main-blog—posts_single—inside»]//a
|
Получение якорного текста
|
|
40. XPath
|
//div[@class=»main-blog—posts_single—inside»]//a
|
Исходный код ссылки
|
|
41. XPath
|
//div[@class=»main-blog—posts_single—inside»]//a/@href
|
Содержимое URL
|
|
42. XPath
|
//div[contains(@class ,’main-blog—posts_single-inner—text—inner’)]//h3|//a[@class=»comments-link»]
|
Несколько правил в одном выражении
|
|
43. XPath
|
//div[contains(@class, ‘rating-box’)]
|
Парсинг рейтинга
|
|
44. XPath
|
//div[contains(@class, ‘rating-box’)]
|
Парсинг рейтинга
|
|
45. XPath
|
//div[contains(@class, ‘right-text’)]/span[1]
|
Парсинг цены товара
|
|
46. XPath
|
//div[contains(@class, ‘video-line’)]/iframe
|
Количество видео на странице по классу
|
|
47. XPath
|
//h1/text()
|
Получение h1 страницы
|
|
48. XPath
|
//h3
|
Содержимое всех подзаголовков H3
|
|
49. XPath
|
//head/link[@rel=’amphtml’]/@href
|
Ищем ссылки на APM-версии страниц
|
|
50. XPath
|
//iframe/@src
|
Все URL в контейнерах IFrame
|
|
51. XPath
|
//iframe[contains(@src ,’www.youtube.com/embed/’)]
|
Ищем все URL в IFrame, которые содержат Youtube
|
|
52. XPath
|
//iframe[not(contains(@src, ‘https://www.googletagmanager.com/’))]/@src
|
Ищем все URL в IFrame, которые не содержат GTM
|
|
53. XPath
|
//meta[@name=’description’]/@content
|
Содержимое мета-тега Description
|
|
54. XPath
|
//meta[@name=’robots’]/@content
|
Получение значений мета Robots (Index/Noindex)
|
|
55. XPath
|
//meta[@name=’theme-color’]/@content
|
Содержимое мета-тега цвета шапки для мобильной версии
|
|
56. XPath
|
//meta[@name=’viewport’]/@content
|
Содержимое тега Viewport
|
|
57. XPath
|
//meta[starts-with(@property, ‘fb:page_id’)]/@content
|
Содержимое разметки Open Graph 1
|
|
58. XPath
|
//meta[starts-with(@property, ‘og:title’)]/@content
|
Содержимое разметки Open Graph 2
|
|
59. XPath
|
//meta[starts-with(@property, ‘twitter:title’)]/@content
|
Содержимое разметки Open Graph 3
|
|
60. XPath
|
//span[@class=»example»]
|
Содержимое по классу
|
|
61. XPath
|
//table[@class=»chars-t»]/tbody/tr[2]/td[2]
|
Парсинг определенных ячеек в таблице 1
|
|
62. XPath
|
//table[@class=»chars-t»]/tbody/tr[4]/td[2]
|
Парсинг определенных ячеек в таблице 2
|
|
63. XPath
|
//title/text()
|
Получение title страницы
|
|
64. XPath
|
/descendant::h3[1]
|
Содержимое первого по списку подзаголовка H3
|
|
65. XPath
|
/descendant::h3[position() >= 0 and position() <= 10]
|
Содержимое первых 10 по списку подзаголовков H3
|
|
66. XPath
|
count(//h3)
|
Число подзаголовков H3
|
|
67. XPath
|
product: «(.*?)»
|
Структурированные данные JSON-LD 1
|
|
68. XPath
|
ratingValue: «(.*?)»
|
Структурированные данные JSON-LD 2
|
|
69. XPath
|
reviewCount: «(.*?)»
|
Структурированные данные JSON-LD 3
|
|
70. XPath
|
string-length(//h3)
|
Длина извлеченной строки
|
|
71. XPath
|
//a[contains(@rel,’ugc’)]/@href
|
UGC
|
|
72. XPath
|
//a[contains(@rel,’sponsored’)]/@href
|
Sponsored
|
|
73. XQuery
|
if (count(//a[starts-with(@href, ‘mailto:’)])) then «Есть почта» else «Нет почты»
|
Проверить, есть Email на странице или нет
|
|
74. XQuery
|
for $a in //li return $a
|
Получить содержимое всех элементов списка LI
|
|
75. HTML templates
|
<table id=»t2″><template:loop><tr><td></td><td>{text()}</td></tr></template:loop></table>
|
Поиск таблицы с атрибутом id=»t2″ и извлечение текста из второго столбца
|
|
76. HTML templates
|
<table id=»t2″><tr></tr><tr><template:loop><td>{text()}</td></template:loop></tr></table>
|
Извлечение данных из второй строки таблицы
|
|
77. HTML templates
|
<table id=»t2″>{_tmp := 0}<template:loop><tr><td>{_tmp := $_tmp + .}</td></tr></template:loop>{result := $_tmp}</table>
|
Вычисление суммы чисел в колонке таблицы
|


